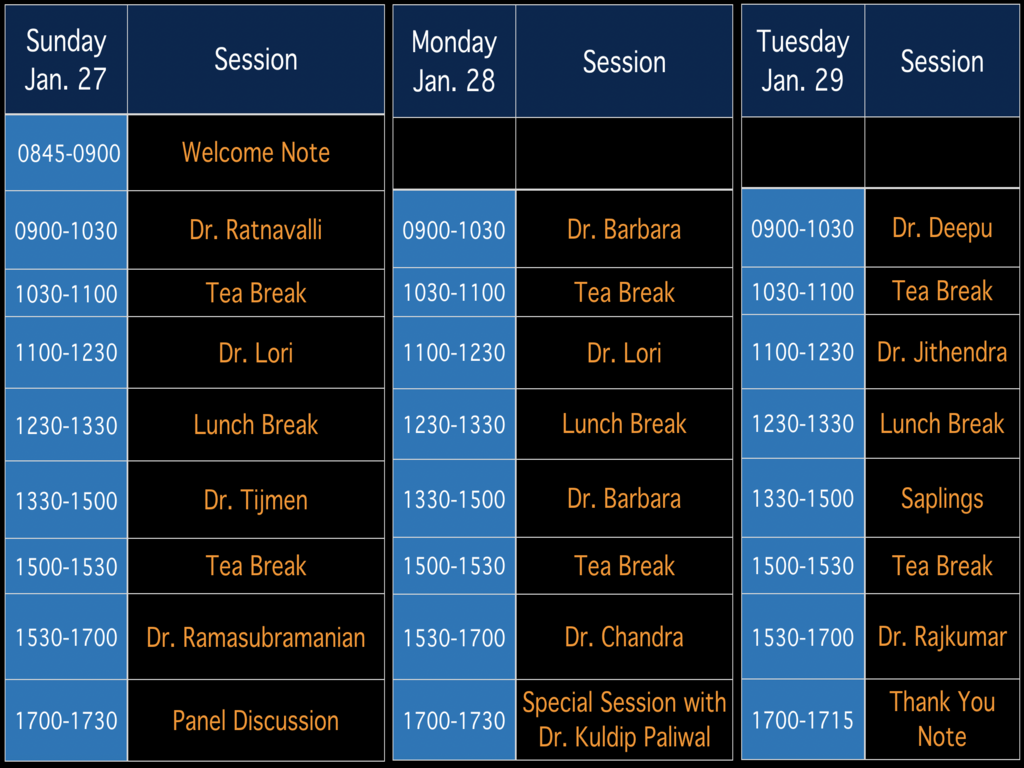
Speakers
Know more about our invited experts


Lori L. Holt
Dr. Holt is an expert in auditory cognitive neuroscience, with a focus on understanding how humans interpret the complexity of spoken language. Her research program builds from considering human speech recognition as arising from general, and not uniquely human or speech-specific, mechanisms. Her training includes single-unit electrohphysiology and animal behavioral models of audition in addition to human behavioral methods across development. Her current research program exploits human psychophysics and learning paradigms in adults and children, human electrophysiology, neuroimaging, animal behavioral models and acoustic analyses.More here.

Barbara Shinn-Cunningham
Barbara Shinn-Cunningham (born 1964) is Director of the Carnegie Mellon University Neuroscience Institute and a Professor of Psychology, Electrical and Computer Engineering, and Biomedical Engineering. Prior to moving to Carnegie Mellon, she was a Professor of Biomedical Engineering at Boston University (BU). She attended Brown University as an undergraduate, where she earned an Sc.B. in Electrical Engineering. She earned both her master's degree and Ph.D. from the Massachusetts Institute of Technology in Electrical and Computer Engineering. She worked at Bell Communications Research, MIT Lincoln Laboratory, and Sensimetrics before joining the faculty at BU. She is an auditory neuroscientist best known for her work on attention and the cocktail party problem, sound localization, and the effects of room acoustics and reverberation on hearing.More here.

Jithendra Vepa
I received Ph.D. from The University of Edinburgh, Scotland in 2004 for the research work on text-to-speech synthesis. Later, I worked on Automatic Speech Recognition (ASR) as a research scientist in IDIAP research institute (affiliated to EPFL, Switzerland) for about 3 years before relocating to India. After working around two and half years at Philips research on Bio-medical Signal Processing, joined Samsung R & D to set up a Speech team. At Samsung, built a team of more than 60 speech technology researchers, engineers & linguists and developed various speech technologies; Text-to-Speech, Blind Source Separation, Automatic Speech Recognition (both Embedded and Cloud-based ASR) and Wakeword Recognition. Some of our work is commercialized in Samsung flagship products, one of the notable contribution is ASR for Global English in Samsung personal voice assistant, Bixby. Recently, I moved to a startup, Observe AI, as Chief Scientist and working on building voice AI platform for call centers. I have more than 35+ publications in peer-reviewed international conferences and journals, also filed 8 patent applications. I am senior member of IEEE and reviewer for various IEEE and ISCA conferences.More here.

Deepu Vijayasenan
He obtained his PhD in Speaker Diarization from Swiss Federal institute of Technology Lausanne in 2010. Subsequently he had worked as a post doctoral researcher in University of Saarbreucken. He is currently an assistant professor in the Department of E& C Engineering, at the National Institute of Technology Karnataka, Surathkal. His main interests are speech signal processing and machine learning. More here.

V Ramasubramanian
Ramasubramanian obtained his B.S. degree from the University of Madras in 1981, B.E. degree from Indian Institute of Science, Bangalore in 1984 and the Ph.D. degree from Tata Institute of Fundamental Research (TIFR), Bombay in 1992. He has been engaged in research in speech processing and related areas for nearly 3 decades. Prior to the present position, he was Professor at PES Institute of Technology, South Campus, Bangalore, 2013-2017. He has worked in various institutions and universities, such as TIFR, Bombay (1984-99) as Research Scholar, Fellow and Reader; University of Valencia, Spain as Visiting Scientist (1991-92); Advanced Telecommunications Research (ATR) Laboratories, Kyoto, Japan as Invited Researcher (1996-97); Indian Institute of Science (IISc), Bangalore as Research Associate (2000-04) and Siemens Corporate Research & Technology (2005-13) as Senior Member Technical Staff and as Head of Professional Speech Processing - India (2006-09). He has over 65 research publications in these areas in peer reviewed international journals and conferences. He is inventor / co-inventor of 14 patents filed in India, Europe and USA. More here.

Ratnavalli Ellajosyula
Manipal Hospital & Annasawmy Mudaliar General HospitalRatnavalli Ellajosyula
Dr. Ratnavalli Ellajosyula was on the faculty of the National Institute of Mental Health & Neurosciences (NIMHANS), Bangalore for 11 years from 1993 to 2004 where she established the first memory clinic in the country in 1998. She is currently a consultant Neurologist at Manipal Hospital, Bangalore, where she also headed the department, and started the DNB training in Neurology. She has been running the cognitive disorders clinic at Manipal Hospital and Annasawamy Mudaliar general hospital for several years and receives referrals from all over India. Her current research focuses on clinical and neuropsychological features of degenerative dementias, in particular frontotemporal dementias, understanding the neural representation and processing of language in bilinguals and neural basis of memory disorders. She was awarded the Commonwealth Fellowship in 1999 and underwent advanced training in diagnosis and neuropsychology of dementias at University of Cambridge, UK. She was a research fellow at the University of North Carolina, Chapel Hill, USA in 2005. She received the Gandhi International Research Fellowship award in the House of Lords, UK in 2016. More here.

Rajakrishnan Rajkumar
Rajakrishnan Rajkumar's research interests lie at the intersection of natural language generation and computational psycholinguistics. His recent research has looked at modelling production choices in English and Hindi using cogntively motivated measures of language comprehension and production. In the past, he has also conducted eye-tracking experiments to study the comprehension of synthesized speech. After completing an undergraduate degree in Industrial Engineering from the College of Engineering Trivandrum (CET), he did a MA in Linguistics from Jawaharlal Nehru University. Subsequently, after completing a PhD in Computational Linguistics from The Ohio State University, he taught at IIT Delhi for 5 years and now teaches at the Indian Institute of Science Education Research (IISER), Bhopal, India.

Chandra Sekhar Seelamantula
Chandra Sekhar Seelamantula is an Associate Professor at the Department of Electrical Engineering, Indian Institute of Science (IISc), Bangalore (since 2009). Prior to joining IISc, he was a postdoctoral fellow at the Ecole polytechnique federale de Lausanne (2006-2009). He received a PhD degree from IISc in 2006. He is an Associate Editor of IEEE Transactions on Image Processing and a Senior Area Editor of IEEE Signal Processing Letters. His current interests are at the interface between signal processing and deep learning. He is a recipient of the Priti Shankar Teaching Award from IISc and the Digital Health Prize from the Biotechnology Industry Research Assistance Council.

Tijmen Tieleman
After obtaining a PhD in Deep Learning from Geoffrey Hinton's Toronto research group in 2014, Tijmen Tieleman joined minds.ai, and now serves as its CEO & CTO. His main interests, besides Deep Learning, are in algorithms, probability theory, and the theory of mathematics & computer programming.